Learning Rate Scheduling
The learning rate is the most important hyperparameter in deep learning. Learning rate scheduling adjusts it during training to achieve faster convergence and better final performance.
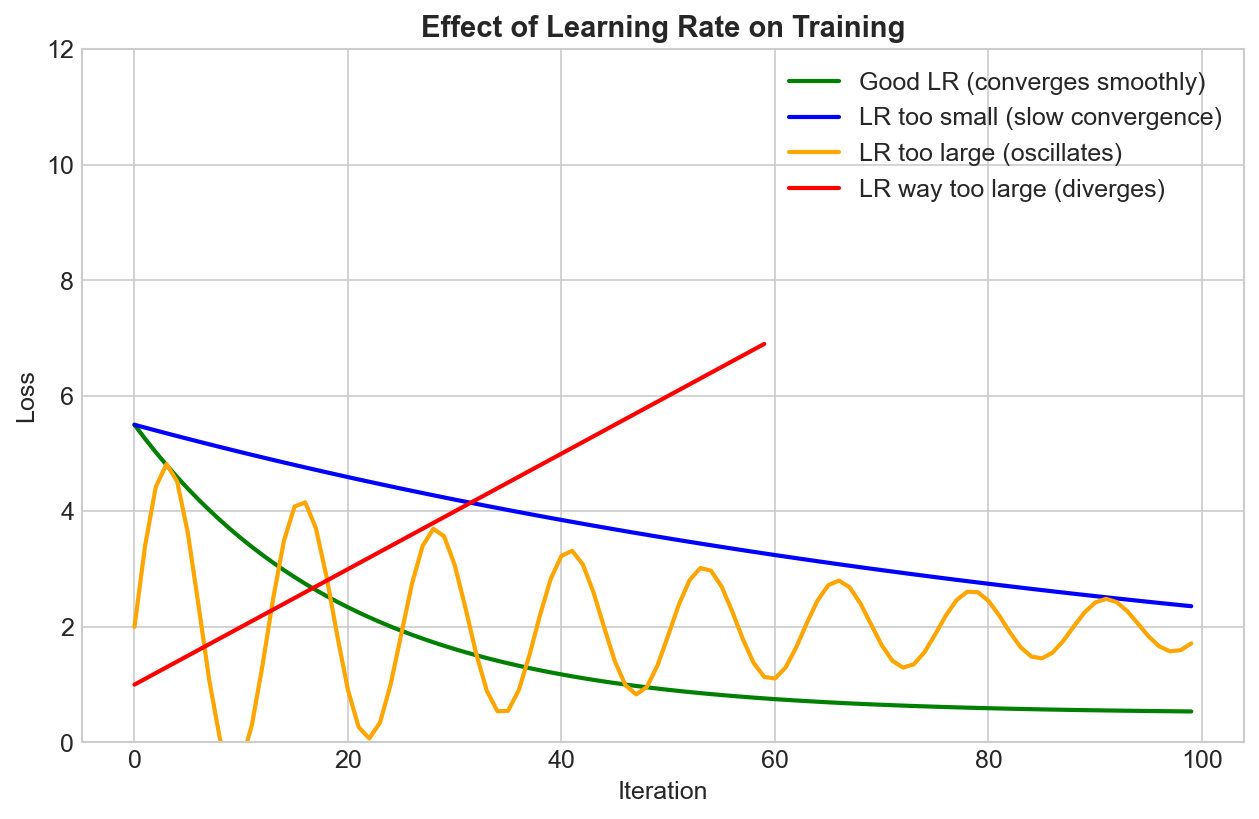
Why Schedule the Learning Rate?
The Dilemma
- Large LR: Fast initial progress, but may overshoot minimum
- Small LR: Precise convergence, but slow and may get stuck
The Solution
Start high (fast progress) → decrease over time (precise convergence)
Loss
|\
| \ High LR: Fast but unstable
| \___
| \___ Low LR: Slow but precise
| \____
|_______________
Epochs
Common Schedules
Step Decay
Reduce LR by factor every N epochs:
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
# LR × 0.1 every 30 epochs
LR: 0.1 → 0.01 → 0.001 → ...
|________|________|____
30 60 90 epochs
Multi-Step Decay
Reduce at specific milestones:
scheduler = MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1)
Exponential Decay
Multiply by gamma every epoch:
scheduler = ExponentialLR(optimizer, gamma=0.95)
# LR_new = LR × 0.95 each epoch
Cosine Annealing
Smooth cosine curve from initial to minimum LR:
scheduler = CosineAnnealingLR(optimizer, T_max=100, eta_min=1e-6)
LR
|\
| \ /\
| \ / \
| \/ \
|__________
Epochs
Cosine Annealing with Warm Restarts
Cosine schedule that restarts periodically:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2)
Restarts can help escape local minima.
Linear Decay
Linear decrease from initial to final LR:
# Common in NLP/transformers
scheduler = LinearLR(optimizer, start_factor=1.0, end_factor=0.0, total_iters=100)
Reduce On Plateau
Reduce when metric stops improving:
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10)
# Reduce by 10x if no improvement for 10 epochs
# In training loop:
scheduler.step(val_loss)
Warmup
Gradually increase LR at the start of training:
LR
| ______
| /
| /
| /
|__/____________
warmup training
Why Warmup?
- Large gradients early in training with random weights
- High LR + large gradients = instability
- Warmup lets model find stable region first
Linear Warmup
def linear_warmup(epoch, warmup_epochs, initial_lr):
if epoch < warmup_epochs:
return initial_lr * (epoch + 1) / warmup_epochs
return initial_lr
Warmup + Cosine Decay (Common Pattern)
from transformers import get_cosine_schedule_with_warmup
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=1000,
num_training_steps=10000
)
Cyclical Learning Rates
Triangular
Oscillate between bounds:
scheduler = CyclicLR(optimizer, base_lr=1e-4, max_lr=1e-2, mode='triangular')
One Cycle
Single cycle: increase then decrease:
scheduler = OneCycleLR(
optimizer,
max_lr=1e-2,
total_steps=1000,
pct_start=0.3 # 30% warmup
)
LR
| /\
| / \
| / \
| / \____
|/_____________
30% 100%
Often achieves better results faster!
Finding the Initial Learning Rate
LR Range Test
- Start with very small LR
- Increase exponentially each batch
- Plot loss vs LR
- Choose LR where loss decreases fastest
from torch_lr_finder import LRFinder
lr_finder = LRFinder(model, optimizer, criterion)
lr_finder.range_test(train_loader, end_lr=10, num_iter=100)
lr_finder.plot()
Loss
|\ /
| \ /
| \_____/
| ↑
| Sweet spot
|___________
LR (log scale)
Best Practices
General Guidelines
| Scenario | Schedule |
|---|---|
| Training from scratch | Cosine or step decay |
| Fine-tuning | Linear decay with warmup |
| Quick training | OneCycleLR |
| Uncertain | ReduceLROnPlateau |
Typical Values
# Vision (SGD)
initial_lr = 0.1
# Vision (Adam)
initial_lr = 1e-3 to 3e-4
# NLP/Transformers
initial_lr = 1e-5 to 5e-5
warmup = 5-10% of training
Common Patterns
ResNet-style:
StepLR(optimizer, step_size=30, gamma=0.1)
Transformer-style:
get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=num_steps // 10,
num_training_steps=num_steps
)
Fast.ai style:
OneCycleLR(optimizer, max_lr=find_lr(), total_steps=...)
Code Template
# Training loop with scheduler
for epoch in range(num_epochs):
for batch in train_loader:
optimizer.zero_grad()
loss = criterion(model(batch), targets)
loss.backward()
optimizer.step()
# Step scheduler per batch (for OneCycle, Cosine, etc.)
scheduler.step()
# Or step per epoch (for StepLR, etc.)
# scheduler.step()
# For ReduceLROnPlateau
# val_loss = validate()
# scheduler.step(val_loss)
Key Takeaways
- Learning rate scheduling improves convergence and final performance
- Start high, decay over time is the general principle
- Warmup helps stabilize early training
- OneCycleLR often gives fast, good results
- ReduceLROnPlateau is safe when uncertain
- Use LR range test to find initial learning rate