Gradient Descent
Gradient descent is the workhorse optimization algorithm behind most machine learning models. It's the fundamental technique that allows neural networks to learn from data by iteratively adjusting weights to minimize errors.
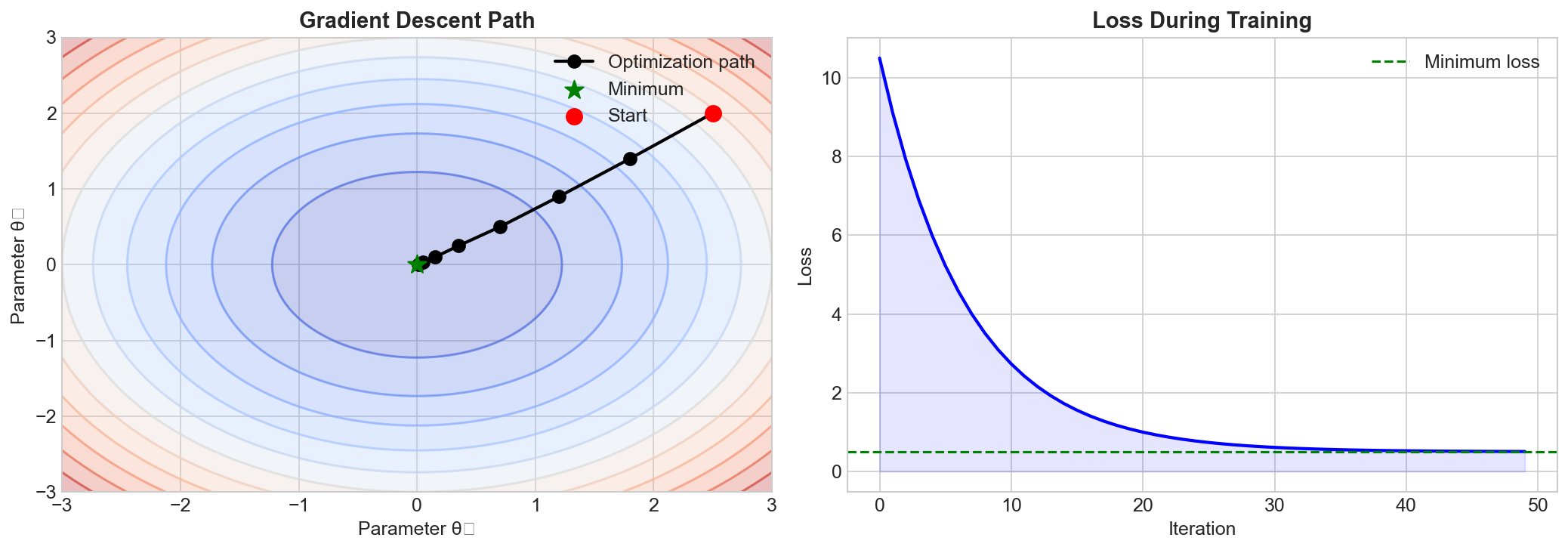
What is Gradient Descent?
At its core, gradient descent is an iterative optimization algorithm used to find the minimum of a function. In machine learning, this function is typically a loss function that measures how wrong our model's predictions are.
The key insight is simple: if you want to go downhill, take steps in the direction of steepest descent. The gradient tells us exactly that direction.
The Algorithm
The update rule for gradient descent is:
θ = θ - α * ∇J(θ)
Where:
- θ (theta) represents the model parameters (weights)
- α (alpha) is the learning rate - how big our steps are
- ∇J(θ) is the gradient of the loss function with respect to parameters
Types of Gradient Descent
Batch Gradient Descent
Computes gradients using the entire training dataset. Stable but slow for large datasets.
Stochastic Gradient Descent (SGD)
Updates parameters using one training example at a time. Faster but noisier.
Mini-batch Gradient Descent
The best of both worlds - uses small batches (typically 32-256 examples). This is the most common approach in practice.
Learning Rate: The Critical Hyperparameter
The learning rate α is arguably the most important hyperparameter:
- Too large: The algorithm may overshoot and diverge
- Too small: Training becomes painfully slow
- Just right: Smooth convergence to a good minimum
Common Challenges
- Local minima: Getting stuck in suboptimal solutions
- Saddle points: Points where gradient is zero but it's not a minimum
- Vanishing gradients: Gradients become too small in deep networks
- Exploding gradients: Gradients become too large, causing instability
Modern Variants
Many improvements build on basic gradient descent:
- Momentum: Accumulates velocity to escape local minima
- AdaGrad: Adapts learning rate per parameter
- RMSprop: Addresses AdaGrad's diminishing learning rates
- Adam: Combines momentum and adaptive learning rates
In Practice
When training neural networks, you'll almost always use an optimizer like Adam or SGD with momentum rather than vanilla gradient descent. These variants handle many of the challenges automatically and typically converge faster.
Key Takeaways
- Gradient descent minimizes the loss function by following the negative gradient
- The learning rate controls the step size - tuning it is critical
- Mini-batch gradient descent is the standard approach in deep learning
- Modern optimizers like Adam improve on basic gradient descent significantly