Decision Trees
Decision trees are one of the most interpretable machine learning models. They make predictions by learning a series of if-then-else decision rules from the data.
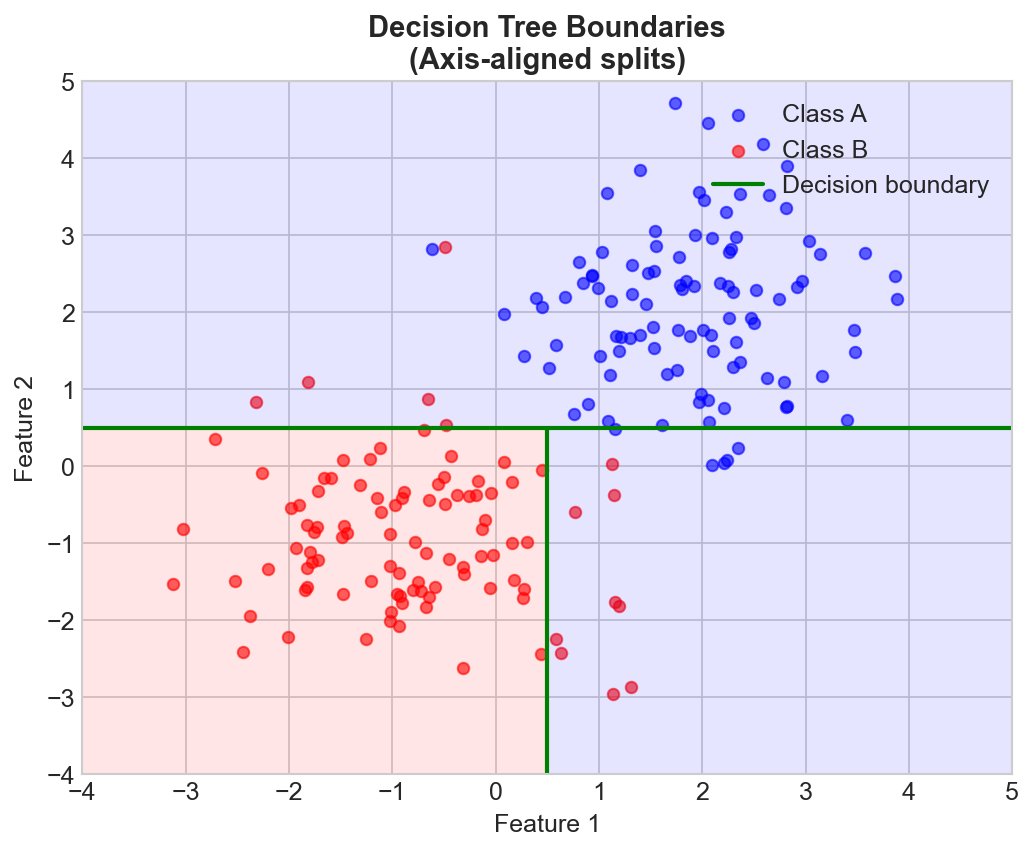
How They Work
A decision tree splits data recursively based on feature values:
[Is age > 30?]
/ \
Yes No
| |
[Income > 50k?] [Student?]
/ \ / \
Yes No Yes No
| | | |
[Buy: Yes] [Buy: No] [Buy: Yes] [Buy: No]
Each internal node tests a feature, each branch represents an outcome, and each leaf node makes a prediction.
Building a Tree
The Recursive Algorithm
- Select the best feature to split on
- Create child nodes for each outcome
- Recursively repeat for each child
- Stop when a stopping criterion is met
Choosing the Best Split
The key question: which feature should we split on?
For Classification: Gini Impurity
Gini = 1 - Σ pᵢ²
Measures how "mixed" the classes are. Lower is better.
For Classification: Entropy
Entropy = -Σ pᵢ × log₂(pᵢ)
Information gain = parent entropy - weighted average child entropy.
For Regression: Variance Reduction
Choose splits that minimize variance within each group.
Stopping Criteria
Without stopping rules, trees grow until each leaf is pure (overfitting!).
Common criteria:
- Maximum depth reached
- Minimum samples per leaf
- Minimum information gain
- Maximum number of leaves
Advantages
- Interpretable: Easy to explain and visualize
- No feature scaling needed: Works with raw values
- Handles mixed types: Numerical and categorical
- Fast prediction: Just traverse the tree
- Captures non-linear relationships: Through multiple splits
Disadvantages
- High variance: Small data changes → different trees
- Prone to overfitting: Deep trees memorize data
- Greedy: Locally optimal splits, not globally optimal
- Axis-aligned: Can only split parallel to feature axes
- Unstable: Sensitive to training data
Important Hyperparameters
| Parameter | Effect |
|---|---|
| max_depth | Deeper = more complex, more overfitting |
| min_samples_split | Higher = more regularization |
| min_samples_leaf | Higher = smoother predictions |
| max_features | Lower = more randomness, less overfitting |
Pruning
Two approaches to prevent overfitting:
Pre-pruning (Early Stopping)
Stop growing before the tree becomes too complex.
- Set max_depth, min_samples_leaf, etc.
Post-pruning
Grow full tree, then remove branches that don't help.
- Cost-complexity pruning uses a complexity parameter α
Feature Importance
Trees provide a natural measure of feature importance:
- Sum of information gain from all splits using that feature
- Weighted by number of samples reaching those splits
Trees in Practice
Single decision trees are rarely used alone because of high variance. Instead:
- Random Forests: Ensemble of decorrelated trees
- Gradient Boosting: Sequential ensemble correcting errors
- XGBoost/LightGBM: Optimized gradient boosting
These ensemble methods retain interpretability benefits while dramatically improving performance.
Key Takeaways
- Trees make predictions through learned decision rules
- Splits are chosen to maximize information gain (or minimize impurity)
- Easy to interpret but prone to overfitting
- Hyperparameters control the bias-variance tradeoff
- Ensembles (Random Forest, XGBoost) address the variance problem