Activation Functions
Activation functions introduce non-linearity into neural networks. Without them, any deep network would collapse to a single linear transformation.
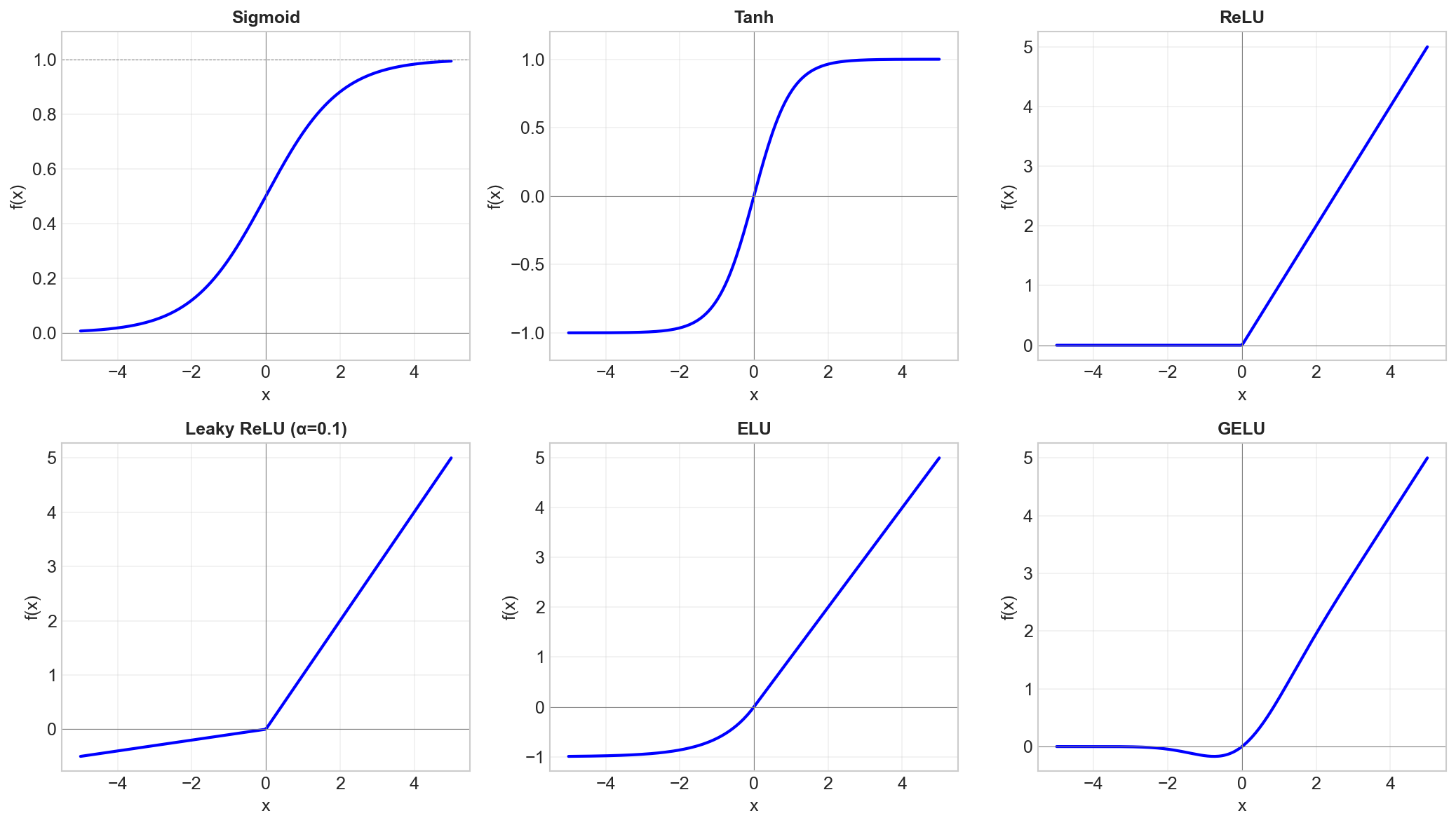
Why Non-linearity?
A stack of linear layers is still linear:
W₃(W₂(W₁x)) = (W₃W₂W₁)x = Wx
Activation functions break this, enabling networks to learn complex patterns.
Classic Activation Functions
Sigmoid
σ(x) = 1 / (1 + e^(-x))
Range: (0, 1)
Pros:
- Smooth, differentiable
- Output interpretable as probability
Cons:
- Vanishing gradients: σ'(x) ≤ 0.25
- Outputs not zero-centered
- Expensive (exponential)
Use: Output layer for binary classification.
Tanh
tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x))
Range: (-1, 1)
Pros:
- Zero-centered outputs
- Stronger gradients than sigmoid
Cons:
- Still has vanishing gradients
- Expensive
Use: RNNs (historically), rarely in modern networks.
Modern Activation Functions
ReLU (Rectified Linear Unit)
ReLU(x) = max(0, x)
Range: [0, ∞)
Pros:
- Simple and fast
- No vanishing gradient for x > 0
- Sparsity (neurons can be "off")
- Enabled training of very deep networks
Cons:
- "Dying ReLU": Neurons stuck at zero forever
- Not zero-centered
- Unbounded (can explode)
Use: Default choice for hidden layers.
Leaky ReLU
LeakyReLU(x) = x if x > 0 else αx
Typically α = 0.01
Pros:
- Prevents dying ReLU
- Almost as simple as ReLU
Cons:
- α is another hyperparameter
- Marginal improvement in practice
PReLU (Parametric ReLU)
PReLU(x) = x if x > 0 else αx
Same as Leaky ReLU but α is learned.
ELU (Exponential Linear Unit)
ELU(x) = x if x > 0 else α(e^x - 1)
Pros:
- Smooth at x = 0
- Negative values push mean toward zero
- Self-normalizing properties
Cons:
- More expensive than ReLU
SELU (Scaled ELU)
SELU(x) = λ × ELU(x, α)
With specific values of λ and α that maintain unit variance.
Use: Self-normalizing networks (no batch norm needed).
GELU (Gaussian Error Linear Unit)
GELU(x) = x × Φ(x)
Where Φ is the Gaussian CDF.
Pros:
- Smooth
- Works exceptionally well in transformers
- Combines properties of ReLU and dropout
Use: Transformers, modern architectures (BERT, GPT).
Swish / SiLU
Swish(x) = x × σ(βx)
Often with β = 1.
Pros:
- Smooth, bounded below
- Sometimes outperforms ReLU
Use: EfficientNet, modern CNNs.
Comparison Table
| Function | Range | Zero-centered | Vanishing | Dead neurons |
|---|---|---|---|---|
| Sigmoid | (0,1) | No | Yes | No |
| Tanh | (-1,1) | Yes | Yes | No |
| ReLU | [0,∞) | No | No* | Yes |
| Leaky ReLU | (-∞,∞) | No | No | No |
| ELU | (-α,∞) | ~Yes | No | No |
| GELU | (~-0.17,∞) | No | No | No |
Output Layer Activations
Different tasks need different output activations:
| Task | Activation | Loss |
|---|---|---|
| Binary classification | Sigmoid | Binary cross-entropy |
| Multi-class classification | Softmax | Categorical cross-entropy |
| Regression | None (linear) | MSE |
| Bounded regression | Sigmoid/Tanh | MSE |
Choosing Activation Functions
Hidden Layers (2024 recommendations)
- Default: ReLU
- Transformers: GELU
- If ReLU dies: Leaky ReLU or ELU
- Cutting edge: Swish, Mish
Don't
- Use sigmoid/tanh in hidden layers (vanishing gradients)
- Mix too many different activations
- Overthink it (ReLU works great)
The Gradient Flow Perspective
Backprop gradient = upstream_gradient × local_derivative
| Activation | Derivative at typical inputs |
|---|---|
| Sigmoid | 0.1 - 0.25 (shrinks!) |
| ReLU | 0 or 1 (preserves or kills) |
| GELU | ~0 to ~1.1 (smooth) |
ReLU's derivative of 1 for positive inputs is why it enabled deep learning.
Key Takeaways
- Activations add non-linearity - essential for deep learning
- ReLU is the default for hidden layers
- GELU is standard in transformers
- Sigmoid/softmax for output layers (classification)
- Vanishing gradients killed sigmoid/tanh for hidden layers
- Modern activations (GELU, Swish) are smooth variants of ReLU